Macroseismic Intensity Data Online Publisher


Input data management and analysis
Macroseismic intensity data are usually stored in a varied formats: printed tables, maps or text.
The tiding up process performed in order to create a scientific publication requires, among others, reformatting the raw data, georeferencing places on a map, create a list of bibliographical references and obviously mention the main scientific text accompanying the published data.
Think about MIDOP as an alternative way of publishing this material.
By using this tool you can:
- publish a list of earthquakes, based on an earthquake catalogue table;
- publish a map and a table for each earthquake, based on a list of georeferenced places which have been affected by some degree of intensity;
- publish the bibliographical references, based on a reference table;
- publish the scientific study accompanying the data.
The whole process of publishing within MIDOP requires that data tables are well formatted.
The key point of well formatting in MIDOP is the concept of "unique item identifier code". Each basic element must be uniquely identified in order to be able to recall it from other elements.
Some examples of unique identifiers considered in MIDOP:
- every earthquake in the catalogue must have a unique identifier code, as it will be used by its related macroseismic intensity observations;
- every macroseismic intensity observations has a unique identifier;
- places mentioned by macroseismic observations have a unique identifier in all earthquakes; they are used for creating places seismic histories and they might refers to a geographical gazetteer.
Unique identifiers in MIDOP are preferably abstracted codes or simply numbers.
It must be said for example that in historical seismology the origin time cannot be the identifier code, because the big time range uncertainty might cause overlapping earthquakes. A simple solution is to adopt integer numbers, or, if you prefer, a combination of numbers and letters, to make it easier the identification. The unavoidable rule about unique identifiers is to avoid spaces and special characters such as è , ì, ù, ñ, č, @, ç, ^ " ‘ § | ( / …).
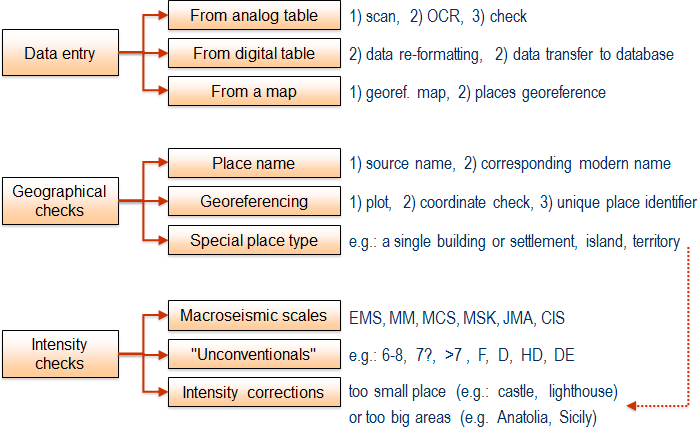
Below a scheme representing the tiding up process of the raw macroseismic data:
The amount of records involved in historical seismology is usually small and its data manipulation is possible using general purpose spreadsheet software such as Microsoft Excel (closed source), LibreOffice Calc or OpenOffice Calc (open source). Spreadsheets are a comfortable solution both for creating new data, organising existing ones, simple analysis and for sharing data with other colleagues. In order to avoid misunderstandings about the transferred data between colleagues, we would like to stress on the importance of always incorporate a description of the data content and a description of each field name used in table.
We encourage users to take a step forward in their data manipulation processes by adopting a relational database system in addition to a spreadsheet.
Packages such as Microsoft Access, OpenOffice Base or Calligra Kexi are relational databases capable of facing complex analysis by using a relatively user friendly interface. These instruments have been created with a series of constraints that helps people avoiding compilation errors that might produce unwanted publication mistakes.
